
北京2024年8月23日 /美通社/ -- 近日,浪潮信息发布源2.0-M32大模型4bit和8bit量化版,性能比肩700亿参数的LLaMA3开源大模型。4bit量化版推理运行显存仅需23.27GB,处理每token所需算力约为1.9 GFLOPs,算力消耗仅为同等当量大模型LLaMA3-70B的1/80。而LLaMA3-70B运行显存为160GB,所需算力为140GFLOPs。
源2.0-M32量化版是"源"大模型团队为进一步提高模算效率,降低大模型部署运行的计算资源要求而推出的版本,通过采用领先的量化技术,将原模型精度量化至int4和int8级别,并保持模型性能基本不变。源2.0-M32量化版提高了模型部署加载速度和多线程推理效率,在不同硬件和软件环境中均能高效运行,降低了模型移植和部署门槛,让用户使用更少的计算资源,就能获取源2.0-M32大模型的强大能力。
源2.0-M32大模型是浪潮信息"源2.0"系列大模型的最新版本,其创新性地提出和采用了"基于注意力机制的门控网络"技术,构建包含32个专家(Expert)的混合专家模型(MoE),模型运行时激活参数为37亿,在业界主流基准评测中性能全面对标700亿参数的LLaMA3开源大模型,大幅提升了模型算力效率。
模型量化(Model Quantization)是优化大模型推理的一种主流技术,它显著减少了模型的内存占用和计算资源消耗,从而加速推理过程。然而,模型量化可能会影响模型的性能。如何在压缩模型的同时维持其精度,是量化技术面临的核心挑战。
源2.0-M32大模型研发团队深入分析当前主流的量化方案,综合评估模型压缩效果和精度损失表现,最终采用了GPTQ量化方法,并采用AutoGPTQ作为量化框架。为了确保模型精度最大化,一方面定制化适配了适合源2.0-M32结构的算子,提高了模型的部署加载速度和多线程推理效率,实现高并发推理;另一方面对需要量化的中间层(inter_layers)进行了严格评估和筛选,确定了最佳的量化层。从而成功将模型精度量化至int4和int8级别,在模型精度几乎无损的前提下,提升模型压缩效果、增加推理吞吐量和降低计算成本,使其更易于部署到移动设备和边缘设备上。
评测结果显示,源2.0-M32量化版在多个业界主流的评测任务中性能表现突出,特别是在MATH(数学竞赛)、ARC-C(科学推理)任务中,比肩拥有700亿参数的LLaMA3大模型。
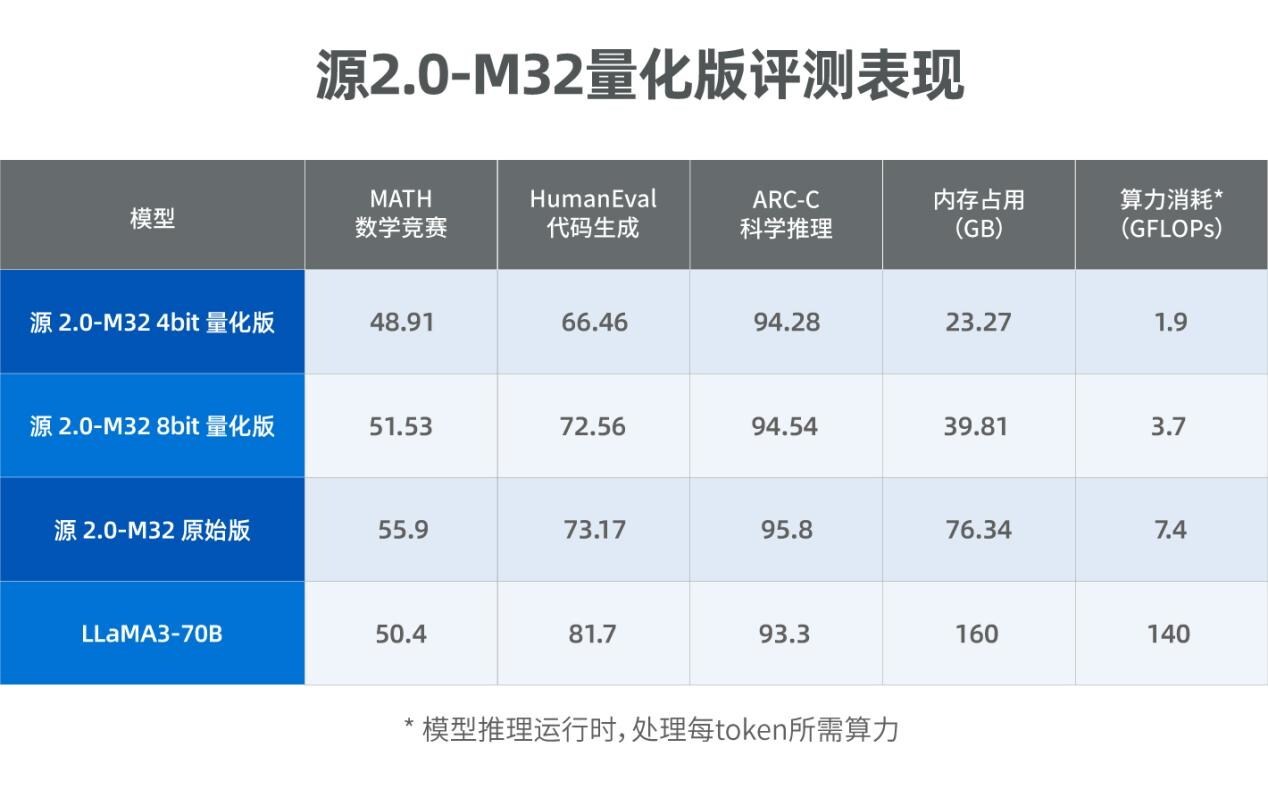
总之,源2.0-M32大模型量化版在保持推理性能的前提下,显著降低了计算资源消耗和内存占用,其采用的GPTQ量化方法通过精细调整,成功将模型适配至int4和int8精度级别。通过定制化算子优化,源2.0-M32量化版实现了模型结构的深度适配和性能的显著提升,确保在不同硬件和软件环境中均能高效运行。未来,随着量化技术的进一步优化和应用场景的拓展,源2.0-M32量化版有望在移动设备和边缘计算等领域发挥更广泛的作用,为用户提供更高效的智能服务。
源2.0-M32量化版已开源,下载链接如下:
Hugging Face平台下载链接:
https://huggingface.co/IEITYuan/Yuan2-M32-gguf-int4
https://huggingface.co/IEITYuan/Yuan2-M32-hf-int4
https://huggingface.co/IEITYuan/Yuan2-M32-hf-int8
modelscope平台下载链接:
https://modelscope.cn/models/IEITYuan/Yuan2-M32-gguf-int4
https://modelscope.cn/models/IEITYuan/Yuan2-M32-HF-INT4
https://modelscope.cn/models/IEITYuan/Yuan2-M32-hf-int8
随机文章

